Overview
CMS Tier-2 center at Purdue consists of dedicated and opportunistic resources on six computing clusters: Hammer, Bell, Gilbreth, Geddes, Negishi and Gautschi.
Hammer, Bell, Negishi and Gautschi are large community clusters maintained by ITaP on which CMS has dedicated and opportunistic access to the job slots. Gilbreth cluster is exclusively dedicated to GPU-enabled workflows. Geddes cluster is currently used for the development of an Analysis Facility at Purdue CMS Tier-2.
Instructions to access the Tier-2 clusters and recommendations about their usage use are given here.
The technical details of the hardware installed at the Tier-2 clusters are listed below.
Resources
Network connections
- Wide area networking
- WAN link to Indiana GigaPOP: 400Gb/s dedicated with 100Gb/s backup path
- Data Center Core and LAN
- Storage cluster ('2550') to Data Center Core ('MATH'): 400 Gb/sec
- Community clusters typically have 100G Infiniband networking.
Computing/Storage nodes
| Name | # nds | job slots | Model | Compute | GPU | Storage |
|
cms-j (retiring in 2024) |
4 (*) |
- |
Advanced HPC |
- |
- |
216TB (*) |
|
cms-k |
10 (*) |
- |
KingStar |
- |
- |
216TB |
|
cms-l (retiring in 2025) |
3 (*) |
- |
Aspen |
- |
- |
288TB |
|
cms-m (retiring in 2025) |
2 (*) |
- |
Aspen |
- |
- |
360TB |
|
cms-n |
1 |
- |
KingStar |
- |
- |
192TB |
|
cms-jb00 |
1 (*) |
- |
SuperMicro JBOD |
- |
- |
840TB |
|
cms-jb01 |
1 |
|
WD JBOD |
- |
- |
1428TB |
|
cms-jb02 |
1 |
|
WD JBOD |
- |
- |
1632TB (102x16TB) |
|
cms-jb03 |
1 | WD JBOD + Dell R6515 |
- | - |
1632TB (102x16TB) |
|
|
cms-jb04 |
1 | WD JBOD + Dell R640 |
- | - | 1428TB (102x14TB) |
|
|
cms-jb05 |
1 | WD JBOD + Dell R640 |
- | - | 1428TB (102x14TB) |
|
|
cms-jb06 |
1 | WD JBOD + SM H12SSW-NT |
1428TB (102x14TB) |
|||
|
cms-jb07 |
1 | WD JBOD + ASUS (ASUS RS500A-E11) |
2040TB (102x20TB) |
|||
|
cms-jb08 |
1 | WD JBOD + ASUS (ASUS RS500A-E11) |
2040TB (102x20TB) |
|||
|
cms-jb09 |
1 | WD JBOD + ASUS (ASUS RS500A-E11) |
2040TB (102x20TB) |
|||
|
dtn00,01 |
2 | ASUS | ||||
|
dtn02-07 |
6 | SM H12SSW-NT | Data Transfer Nodes (dtn06 is currently used as XCache server) |
|||
|
ps-eos |
1 | ASUS K14PA-U24 | PerfSONAR server (close to storage) | |||
|
hammer-d (retired to 2550) |
18 |
864 |
DELL |
48-core (HT-on) Xeon Gold 6126 @ 2.60GHz, 192GB RAM |
- |
- |
|
hammer-e (retired to 2550) |
15 |
720 |
Supermicro |
48-core (HT-on) Xeon Gold 6126 @ 2.60GHz, 96GB RAM |
- |
- |
|
hammer-f,g |
22 |
5632 |
DELL |
256-core (HT-on) AMD EPYC 7702 @ 2GHz, 512GB RAM |
1x nVidia T4 |
- |
|
bell |
9.5 (**)(#) |
1216 |
DELL |
128-core (HT-off) AMD EPYC 7662 @ 2GHz, 256GB RAM |
- |
- |
|
gilbreth |
2 (**) |
- |
DELL |
40-core Xeon Gold 5218R CPU @ 2.10GHz, 192GB RAM |
2x nVidia V100 |
- |
|
geddes CPU |
3 (**) |
- |
DELL |
128-core (HT-off) AMD EPYC 7662 @ 2.0GHz, 512GB RAM |
- |
8TB SSD |
| geddes GPU | 3 (**) | - | DELL PowerEdge R7525 |
128-core (HT-off) AMD EPYC 7662 @ 2.0GHz, 512 GB RAM | 2x nVidia A100 | 8TB SSD |
| Additional Geddes Storage | 4TB SSD | |||||
| negishi-c |
16(**) |
4096 |
DELL |
256-core (HT-on) AMD EPYC 7763 @ 2.2GHz, 512GB RAM |
- |
- |
| negishi-a |
8.5(**) |
1088 (8.5x128) |
DELL |
128-core (HT-on) AMD EPYC 7763 @ 2.2GHz, 512GB RAM |
- |
- |
| gautschi (non-USCMS) |
1(**) |
192 (1x192) |
DELL |
196-core (HT-off) AMD EPYC 9654 @ 2.4GHz, 512GB RAM |
- |
- |
| gautschi |
2 (**) |
192 (1x192) |
DELL |
196-core (HT-off) AMD EPYC 9654 @ 2.4GHz, 512GB RAM |
- |
- |
(**) Nodes purchased through the Community Clusters Program. Hardware not owned by CMS.
- User interface
- cms-fe00/01: (cms.rcac.purdue.edu)
* 2x DELL R420 32-Core, 96GB RAM.
services: log in, grid UI, Condor + SLURM batch, afs client
Serve both the CMS and Hammer clusters.
- cms-fe00/01: (cms.rcac.purdue.edu)
- Gatekeepers/Schedulers
- Purdue-Hammer: (hammer-osg.rcac.purdue.edu) 4-cores, 8 GB RAM VM, services: HTCondor-CE
- Purdue-Bell: (bell-osg.rcac.purdue.edu) 4-cores, 8 GB RAM VM, services: HTCondor-CE
- Purdue-Negishi (osg.negishi.rcac.purdue.edu) 4-cores, 8 GB RAM VM, services: HTCondor-CE
- Analysis Facility
- 3 nodes (paf-a0[0-2].cms.rcac.purdue.edu): 2x AMD EPYC 7662 64-core CPUs, 512GB RAM, 2x T4 GPUs
- 2 nodes (paf-b0[0-1].cms.rcac.purdue.edu); 2x AMD EPYC 7702 64-core CPUs, 512GB RAM, 1x T4 GPU
- 3 virtual nodes (paf-v0[2-4].cms.rcac.purdue.edu); 8 vCPUs, 16GB RAM, 1 T4 GPU passed through to VM.
- ProxMox Virtual Environment Cluster
- 9 SuperMicro 1U nodes. AMD EPYC 7543P 32-Core Processor, 64GB RAM, 2x25Gb NICs
- 3 nodes serve as EOS Management cluster:
- each node runs one QDB-node VM;
- one Highly-available VM, serving the MGM functions, can run on any of the 3 nodes, as availability permits.
- 6 nodes serve as general Data-Transfer nodes, and also implement XCache functions:
- each node runs one XCache disk-server VM, with 2 large NVMe disks attached to it;
- one Highly-available VM, service the XCache Redirector functions, can run on any of the 6 nodes, as availability permits.
- 3 nodes serve as EOS Management cluster:
- 9 SuperMicro 1U nodes. AMD EPYC 7543P 32-Core Processor, 64GB RAM, 2x25Gb NICs
- Miscellaneous
- XCache: Implemented in virtual machines running in the ProxMox deployment:
- 6x disk-server VMs, with 2 large NVMe disks, 16-cores, 16GB of RAM, 2x25Gb NICs.
- 1x redirector. 8-core, 16GB of RAM
- Shoveler: (reporting xrootd stats to central CMS service). VM with 1-core, 2GB of RAM
- CVMFS local repository:
- Stratum-0: VM with 2-cores, 4GB or RAM;
- Stratum-1: VM with 2-cores, 4GB or RAM;
- Squid cache: VM with 2-cores, 4GB or RAM;
- Client/Publisher: VM with 2-cores, 4GB or RAM;
- Squid: Running 6 instances of squid servers in total. Each squid servers runs three instances of squid.
- squid1.rcac.purdue.edu: 8-cores, Intel(R) Xeon(R) CPU E31240 @ 2.1 GHz, 8 GB RAM, service: squid
- squid2.rcac.purdue.edu: 8-cores, Intel(R) Xeon(R) CPU E31240 @ 2.1 GHz, 8 GB RAM, service: squid
- Perfsonar:
- Perfsonar latency node: (perfsonar-cms1.itns.purdue.edu) 8-cores, AMD Opteron(tm) Processor 2380 @ 2.4 GHz, 16 GB RAM, service: latency
- Perfsonar bandwidth node: (perfsonar-cms2.itns.purdue.edu) 8-cores, AMD Opteron(tm) Processor 2380 @ 2.4GHz, 16 GB RAM, service: bandwidth
- XCache: Implemented in virtual machines running in the ProxMox deployment:
Storage:
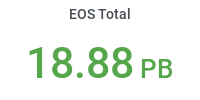
- EOS storage: 7.3 PiB usable (14.6 PiB with replication)
- Shared between central CMS data-management (6.3 PiB) and local users and groups (1 PiB)
- Mounted read-only on the Front-End machines and in the Analysis Facility.
- Accessible from everywhare via XRoot
- j,k,l,m,n nodes from the table above, plus all JBODs (j,k-nodes to be retired at the end of 2024)
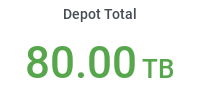
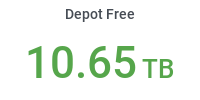
- Depot: 100 TB, shared between local CMS users and groups.
- Shared between local CMS users and groups, and AF users.
- Mounted (read-write) on all nodes (AF and Tier-2 cluster).
- Work-space in Analysis Facility (Geddes): 52 TB of fast (SSD) local storage.
- Shared between Analysis Facility users
- Mounted only in the AF (not accessible in the Tier-2 cluster)
- Shared between Analysis Facility users
- CVMFS
- Read-only storage intended for global distribution of software packages (Conda, Pixi, CMSSW)